
■はじめに
こんにちは。
本記事では、Hinemosエージェントの冗長化により個別ノードでは無くクラスターサービス単位での管理を実現し、フェイルオーバー発生時にもサービスを継続して管理できることを確認したいと思います。
1.前提条件
●実行環境
・マネージャサーバ(OS : Red Hat Enterprise Linux 9)
⇒「Hinemosマネージャ(ver7.2)」
⇒「Hinemos Webクライアント(ver7.2)」
・ノードA(OS : Red Hat Enterprise Linux 9)
⇒「Hinemosエージェント(ver7.2)」
・ノードB(OS : Red Hat Enterprise Linux 9)
⇒「Hinemosエージェント(ver7.2)」
●実施内容
・擬似的なクラスターサービスを構成し、Hinemosエージェントの冗長化を確認する
・疑似クラスターサービスは以下によって構成する
⇒揮発性のVIPの利用
⇒マスター/スタンバイそれぞれ1台ずつのアクティブ/スタンバイ構成
※本記事はクラスターサービスのフェイルオーバー時の確認を行うことが目的である為、
ネットワーク障害対策、データの同期等の実装は対象外となっております。
2.事前準備(疑似クラスター環境)
●ノードAに配置するスクリプト
・以下のスクリプトにより、疑似クラスターサービスの起動を行う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#!/bin/bash VIP=[任意のVIPアドレス] PREFIX=[VIPのプレフィックス] DEVICE=[任意のデバイス名] # VIPの追加 ip addr add "${VIP}/${PREFIX}" dev "${DEVICE}" # ARP通知の発信(IPアドレスとMACアドレスの関連情報を更新) arping -c 3 -A -I "${DEVICE}" "${VIP}" # Hinemosエージェントの起動 systemctl start hinemos_agent # -------------------------------------------------- # 【動確・検証用の疑似フェイルオーバー処理】 # ※実運用では不要な、テスト用の使い捨て処理 # -------------------------------------------------- # 10分間待機 sleep 600 # VIPの削除 ip addr del "${VIP}/${PREFIX}" dev "${DEVICE}" # 再起動(フェイルオーバー実施のため) reboot |
●ノードBに配置するスクリプト
・以下のスクリプトにより、ノードAの停止を検知しフェイルオーバーを行う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#!/bin/bash VIP=[任意のVIPアドレス] PREFIX=[VIPのプレフィックス] DEVICE=[任意のデバイス名] # マスターの稼働状況の確認 while true; do if ping -c 1 -w 1 "${VIP}" > /dev/null 2>&1; then echo "$(date): マスター正常(VIP応答あり)" sleep 1 else echo "$(date): マスター停止を検知(VIP応答なし)" break fi done # マスターの停止を検知後、VIPを追加 echo "$(date): VIPを引き継ぎます" ip addr add "${VIP}/${PREFIX}" dev "${DEVICE}" # ARP通知の発信(IPアドレスとMACアドレスの関連情報を更新) arping -c 3 -A -I "${DEVICE}" "${VIP}" # Hinemosエージェントの起動 systemctl start hinemos_agent |
※本スクリプトの制限事項とリスク
・上記スクリプトは、デモ用にping監視のみで構成された簡易的なものです。
そのため、上記スクリプト利用時にノード間でネットワーク障害が発生した場合、スタンバイ側がマスター側の状態を誤認し、両系で同時にVIPやHinemosエージェントが立ち上がってしまうリスク(スプリットブレイン状態)があります。
・本番環境で運用する場合は本スクリプトは使用せず、必ず Pacemaker 等のクラスターソフトを採用し、ネットワーク障害時にも確実に片系のみが起動する仕様となるよう注意してください。
3.Hinemosエージェントの設定
1.ノードA, BそれぞれにインストールしたHinemosエージェントのhinemos_agent.cfgの以下を変更する
|
1 2 3 4 5 |
### for hostname HOSTNAME=`hostname` ↓ ### for hostname HOSTNAME="demo-test" |
共通のHOSTNAMEを指定することで、どちらのノードがアクティブであっても、Hinemosマネージャ側には「demo-test」という同一エージェントから通信しているように認識させることが可能になります。
2.クラスターサービス監視のため、Hinemosエージェントの自動起動は無効にする
|
1 |
systemctl disable hinemos_agent |
※OS起動時などに両系のHinemosエージェントが同時に起動してしまうと、Hinemosマネージャ側で通信の送信元(実体)が区別できなくなり、「ジョブが意図しないノードで実行される」「監視データが重複・混在して正しいしきい値判定ができない」といった問題が発生するリスクがあります。
そのため、OSの起動と同時にHinemosエージェントが立ち上がらないよう、明示的に自動起動を無効化しておく必要があります。
4.Hinemosマネージャ側の設定
1.事前準備でノードAに配置したスクリプトを実行する
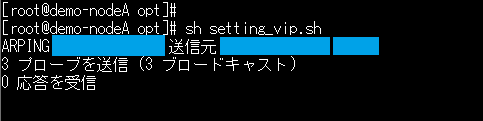
2.ノードAにVIPが割り当てられたことを確認後、ノードBに配置したスクリプトを実行する
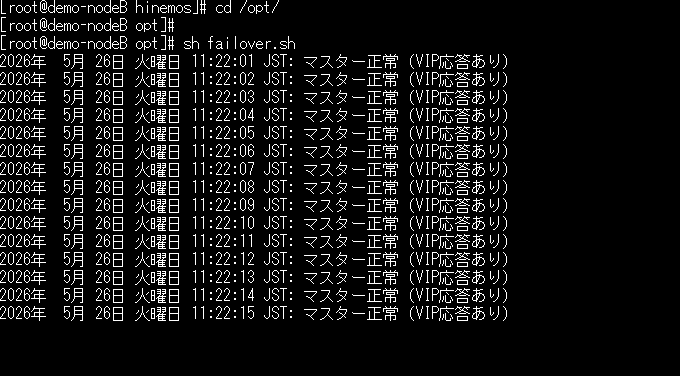
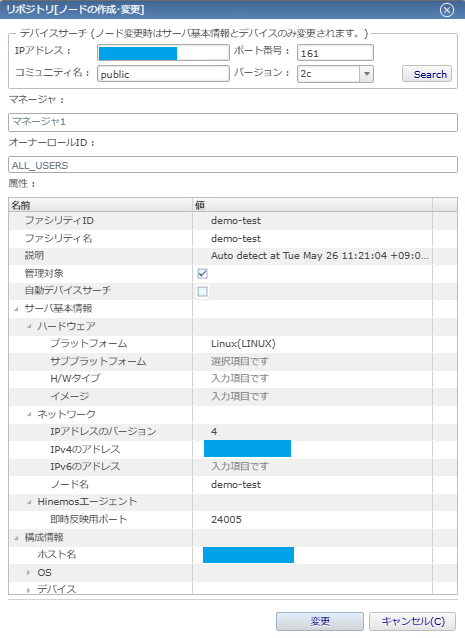
3.「リポジトリ」パースペクティブから、VIPと共通ホスト名を指定してサービスをHinemosマネージャに登録する
4.フェイルオーバー確認用に、以下のコマンドジョブ(cmd01)を作成する
|
1 2 |
スコープ:demo-test コマンド:hostname >> /tmp/hinemos_check.log |
5.フェイルオーバーの確認
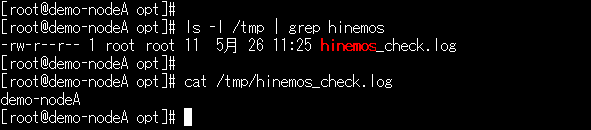
1.コマンドジョブ(cmd01)を実行
コマンドジョブ(cmd01)を実行し、ノードAの「/tmp」に以下の様なファイルが生成されていることを確認してください。

2.フェイルオーバー発生まで待機
スクリプトによりノードAが再起動されるまで待機 or 直接再起動を行ってください。
ノードAの再起動後、ノードBにVIPが割り当てられていることを確認してください。
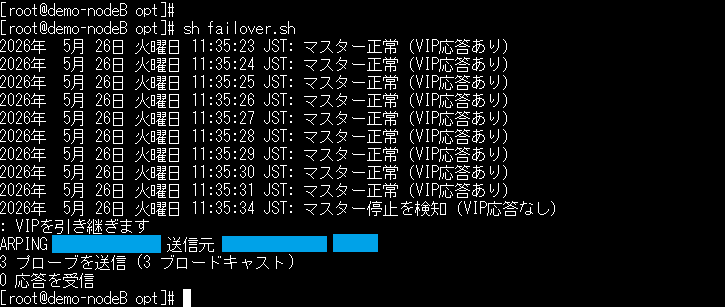
3.フェイルオーバーの確認
コマンドジョブ(cmd01)を実行し、ノードBの「/tmp」に以下の様なファイルが生成されていることを確認してください。


■おわりに
本記事では、VIPの切り替えと「hinemos_agent.cfg」のホスト名共有化を行うことで、
個別ノード単位では無く「クラスターサービス」単位で管理する方法をご紹介いたしました。
これにより、運用者はどちらのノードが動いているかを意識する必要がなくなり、
フェイルオーバー発生時にもHinemosマネージャー側の設定を変えること無く、継続してサービスを管理することが可能となります。
なお、今回はフェイルオーバーの挙動確認をメインとしたためデータの同期等は対象外としましたが、本番環境へ導入する際は、クラスターソフト(Pacemaker等)による厳密な制御や、共有ディスク等を用いたデータ同期の設計を合わせてご検討ください。
Hinemosを用いた可用性の高い監視環境を設計する際の参考になれば幸いです。
最後までお読みいただきありがとうございました!

 Xをフォローする
Xをフォローする
 メルマガに登録する
メルマガに登録する