【Vim】 文字コードの自動認識がうまくいかない時の回避策
投稿日: / 更新日:




この記事は2年以上前に書かれたものです。情報が古い可能性があります。
Hinemos以外のトピック第2弾です。
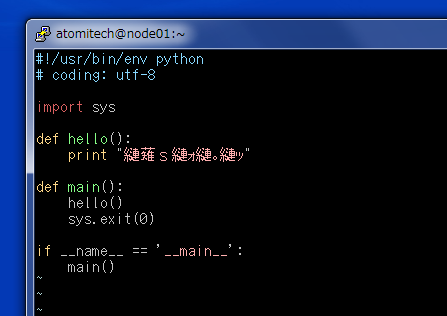
Vimで文字コードを自動認識するための設定を、Webから拝借して.vimrcに入れていますが、それでも正しく認識されないことがよくあります。例えば、最初の数行はASCII文字のみで、その後にUTF-8のマルチバイト文字があるような場合には、必ずといっていいほどCP-932と認識されてしまい、その都度:e ++enc=utf8を入力していました。
Webで調べてみると、自動認識の際の文字コードの順番に問題があるようでした。
参考URL:
vimの文字化けについて – fudist
当方ではUTF-8がメインなので、utf-8を優先するよう、上記URLを参考にして.vimrcに設定を追加してみました。
|
1 2 3 4 5 |
" utf-8優先 let &fileencodings = substitute(&fileencodings, 'utf-8', '_utf-8', 'g') let &fileencodings = substitute(&fileencodings, 'cp932', 'utf-8', 'g') let &fileencodings = substitute(&fileencodings, '_utf-8', 'cp932', 'g') |
2012/05/14 追記:上記の設定でもうまくいかない事があるため、最終的には以下のようにしました。
|
1 2 |
" utf-8優先 set fileencodings=utf-8,cp932,euc-jp,iso-20220-jp,default,latin |
なお、これでも完全に問題を解消できるわけではないため、万が一文字化けが再発した時のために、文字コードの再認識を手軽に行えるキーバインドも追加してみました。
|
1 2 3 4 |
nnoremap ,u :e ++enc=utf8<CR> nnoremap ,s :e ++enc=cp932<CR> nnoremap ,e :e ++enc=ujis<CR> |
これで、日頃の悩みが解消できそうです。以上、VimのちょっとしたTipsをご紹介しました。


