
前回、Hinemos 5.0にHAオプションをインストールするところまでご紹介しました。今回は、監視やジョブを実行している最中にMasterサーバの物理障害を擬似的に発生させ、監視やジョブがどう動くかを検証してみたいと思います。
1. 事前準備
今回は、Masterサーバ側で物理障害を擬似的に発生させますので、監視はStandbyサーバに対して実施し、またジョブもStandbyサーバで実行するものとします。
まず、リポジトリ[ノード]ビュー上で、StandbyサーバをHinemosのリポジトリに登録します。”デバイスサーチ”機能を使用すると便利です。
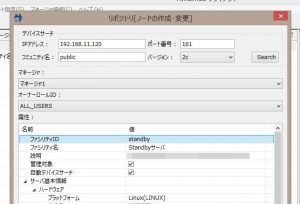
ノードをリポジトリに登録
次に、”CPU使用率”のリソース監視設定を登録し、Standbyサーバを監視対象に指定します(閾値は適当です)。なお、この監視設定に割り当てた通知については、フェイルオーバー時の動作を分かりやすいするため、重要度変化後の初回から通知、かつ、2回目以降も抑制しない設定に変更しています。
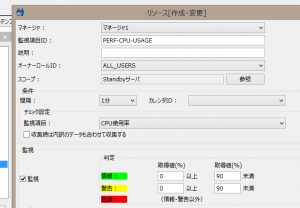
リソース監視設定を登録
続いて、ジョブを設定します。今回は、ジョブ実行中にフェイルオーバーを発生させ、その後の動作を確認したいため、ジョブの起動コマンドに30秒のスリープを入れ、実行時間が長くなるようにしています。
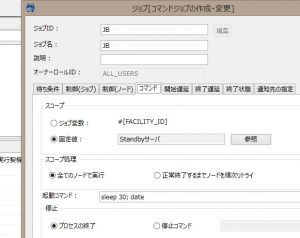
ジョブを設定
事前準備は以上で完了です。
2. フェイルオーバーを試す
それでは、監視とジョブを動かしつつ、Masterサーバの故障を擬似的に発生させて、監視とジョブがどう動くかを見てみます。
なお、私の環境では、MasterサーバもStandbyサーバもVMware上で動作する仮想マシンであるため、「Masterサーバの擬似的な故障」は、VMの電源をオフにすることで行おうと思います。
監視の方は、既に事前準備の時点で1分間隔で動かしていますので、ここではジョブを実行し、その数秒後にMasterサーバのVMを電源オフにしてみます。まずはジョブの実行から。
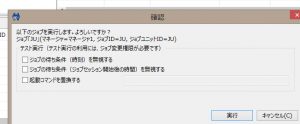
ジョブを実行
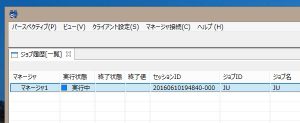
ジョブを実行中
ジョブ履歴パースペクティブ上で、ジョブが実行中になったことを確認できましたので、ここでMasterサーバのVMの電源をオフにします。すると、ここでいったんHinemosマネージャから応答がなくなり、強制的にログアウトとなりました。裏側ではフェイルオーバーが行われているはずです。
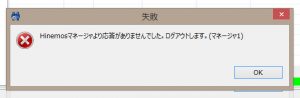
強制的にログアウト
この後も、1分ぐらいログインできない状態が続きましたが、その後無事にログインできるようになりました。この時点で、既にフェイルオーバーが完了しています。
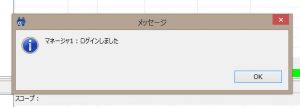
Hinemosマネージャへ再ログイン
ログインしたら、まず、フェイルオーバー前後のイベント通知を見てみます。
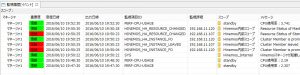
フェイルオーバー前後のイベント通知
CPU使用率のイベントの出力日時を見ると、フェイルオーバー前後の4分間は通知がありません。この間は監視のポーリングが行われず、フェイルオーバー後に自動的に復旧してポーリングが続行されたことが推測できます。
HAオプションのマニュアルによると、”フェイルオーバ中の機能制限”として、PING監視やリソース監視など、スケジューラに依存したプロアクティブな監視(Hinemosマネージャが自発的に行う監視)の動作が一時的に停止する、とあります。今回のリソース監視についても、この制限によって一時的に停止したものと考えられます。
次に、フェイルオーバー直前に実行したジョブの状況を見てみます。
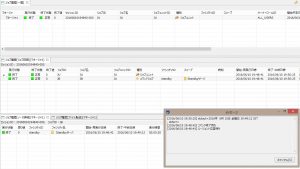
フェイルオーバー直前に実行したジョブの状況
今回、起動コマンドの前半のsleep 30を実行している最中にMasterサーバの電源をオフにしましたが、コマンド自体はHinemosエージェント側で通常どおり実行され、その後のdateコマンドまで正常終了しています。実行時間も30秒と、想定どおりですが、ジョブ自体の終了時刻は、Hinemosマネージャのフェイルオーバーが完了した直後の時刻となっています。
HAオプションのマニュアルによると、”フェイルオーバ中の機能制限”として、新たなジョブの開始や、ジョブの実行状態の遷移については、フェイルオーバー中は行われないようです。確かに、今回のジョブについても、起動コマンドが終了した時点ではHinemosマネージャがフェイルオーバー中だったため、直ちにジョブ自体の終了にはなりませんでした。
ともあれ、フェイルオーバー前に実行されたジョブの起動コマンドについては、フェイルオーバーの影響を受けずにそのまま実行されることが確認できました。
なお、最後にフェイルオーバー後のクラスタの状態を確認してみます。Masterサーバは電源がオフになっていて操作できないため、Standbyサーバへsshでログインし、以下のコマンドを実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# /opt/hinemos/bin/hinemos_ha_status.sh Cluster Controller is running. 14969 java -Djdk.xml.entityExpansionLimit=0 -server -Dprogram.(省略) updated at yyyy-mm-dd hh:mm:ss +0900 [Instances] 192.168.11.120 : MASTER (*) [Plugins] InternalNetworkMonitor : STARTED DiskMonitor : STARTED LoggingReloadPlugin : STARTED ExternalNetworkMonitor : STARTED InstanceManager : STARTED CustomMonitor : STARTED [Resources] VirtualIPAddress : MASTER HinemosPostgreSQL : MASTER HinemosJavaVM : MASTER SnmpTrapForwarder : MASTER ClusterEventNotifier : MASTER SyslogForwarder : MASTER HinemoStatusManager : MASTER |
[Instances]を見ると、MASTERと表示されています。これは、それまでStandbyだったサーバが、フェイルオーバーによってMasterに昇格したことを示しています。
以上で、Masterサーバの擬似的な物理障害によって、想定どおりフェイルオーバーを発生させ、その前後の監視やジョブの動作を確認することができました。
なお本記事では、HAオプションの細かい動作や仕様が十分説明できていないため、あくまで一例として捉えていただけますと幸いです。機会があれば、もう少し詳しい動作についても、検証してご紹介したいと思います。
前回の記事でもお伝えしましたが、Hinemos HAオプションは有償オプションとなっており、Hinemosパートナー企業から購入することが可能です。弊社でも取り扱っておりますので、興味のある方は弊社営業窓口へお問い合わせください。

 Xをフォローする
Xをフォローする
 メルマガに登録する
メルマガに登録する